Neural networks, which learn to perform tasks such as including speech-recognition, automatic-translation systems, image recognition systems and time series prediction by analyzing huge sets of training data, have been responsible for the most impressive recent advances in artificial intelligence.
During training, however, a neural net continually adjusts its internal settings in ways that even its creators can’t interpret. Much recent work in computer science has focused on clever techniques for determining just how neural nets do what they do. Neural nets are so named because they roughly approximate the structure of the human brain. Typically, they’re arranged into layers, and each layer consists of many simple processing units — nodes — each of which is connected to several nodes in the layers above and below. Data are fed into the lowest layer, whose nodes process it and pass it to the next layer. The connections between layers have different “weights,” which determine how much the output of any one node figures into the calculation performed by the next.
In the case of the speech recognition network, Belinkov and Glass used individual layers’ outputs to train a system to identify “phones,” distinct phonetic units particular to a spoken language. The “t” sounds in the words “tea,” “tree,” and “but,” for instance, might be classified as separate phones, but a speech recognition system has to transcribe all of them using the letter “t.” And indeed, Belinkov and Glass found that lower levels of the network were better at recognizing phones than higher levels, where, presumably, the distinction is less important [MIT].
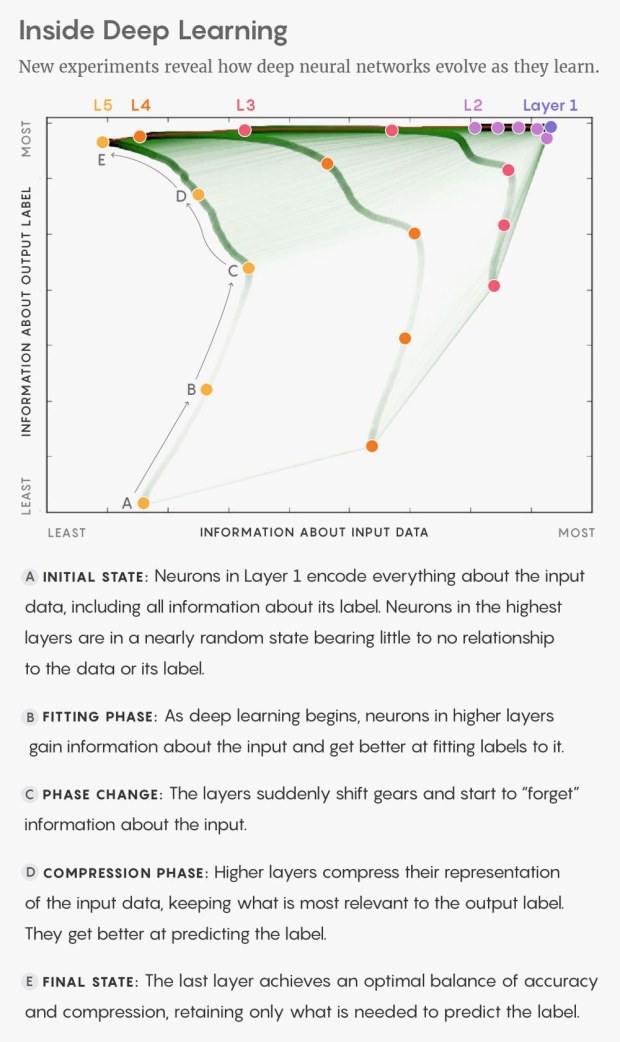
An important part of the neural network is forgetting. An ANN must know, which part to forget and which part not to. The basic algorithm used in the majority of deep-learning procedures to tweak neural connections in response to data is called “stochastic gradient descent”: Each time the training data are fed into the network, a cascade of firing activity sweeps upward through the layers of artificial neurons. When the signal reaches the top layer, the final firing pattern can be compared to the correct label for the image—1 or 0, “dog” or “no dog.” Any differences between this firing pattern and the correct pattern are “back-propagated” down the layers, meaning that, like a teacher correcting an exam, the algorithm strengthens or weakens each connection to make the network layer better at producing the correct output signal. Over the course of training, common patterns in the training data become reflected in the strengths of the connections, and the network becomes expert at correctly labeling the data, such as by recognizing a dog, a word, or a 1.
sources: MIT blog, Wired, arxiv
 satta king gali
satta king gali