Deep Learning is blooming and with it, all kinds of unthought applications have been sprung to life. Every tech company is trying to implement a form of AI in their businesses in some way or the other. Neural networks, after all, have begun to outperform humans in tasks such as object and face recognition and in games such as chess, Go, and various arcade video games. And as we all know, Deep Learning is a manifestation of the human brain and has tremendous potential.
However, An entirely different type of computing has the potential to be significantly more powerful than neural networks and deep learning. This technique is based on the process that created the human brain—evolution. In other words, a sequence of iterative change and selection that produced the most complex and capable machines known to humankind—the eye, the wing, the brain, and so on. The power of evolution is a wonder to behold.
Evolution
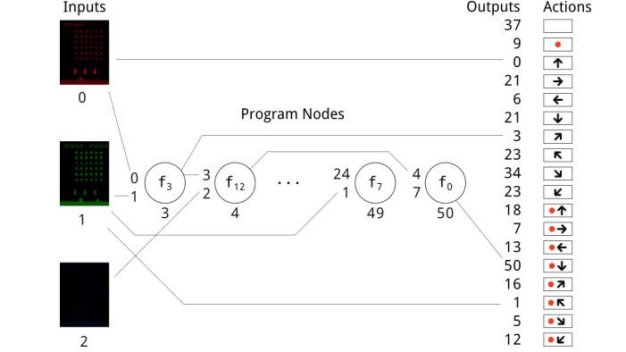
However, the next generation cannot be an identical copy of the first. Instead, it must change in some way. These changes can involve switching two terms in the code—a kind of point mutation. Or they can involve two codes that are cut in half and the halves exchanged—like sexual recombination.
Each of the new generations is then tested to see how well it works. The best pieces of code are preferentially reproduced in another generation, and so on. In this way, the code evolves. Over time, it becomes better, and after many generations, if conditions are right, it can become better than any human coder can design.
via: MitTechReview, Medium



 satta king gali
satta king gali