Researchers from Loughborough University, Western General Hospital, the University of Edinburgh, and the Edinburgh Cancer Centre in the United Kingdom, recently developed a deep learning-based method that can analyze compounds in the human breath and detect illnesses, including cancer, with better than-human average performance.
The sense of smell is used by animals and even plants to identify hundreds of different substances that float in the air. But compared to that of other animals, the human sense of smell is far less developed and certainly not used to carry out daily activities. For this reason, humans aren’t particularly aware of the richness of information that can be transmitted through the air and can be perceived by a highly sensitive olfactory system. AI may be about to change that.
Using NVIDIA Tesla GPUs and the cuDNN-accelerated Keras, and TensorFlow deep learning frameworks, the team trained their neural network on data from participants with different types of cancer receiving radiotherapy, said researcher Angelika Skarysz, a Ph.D. research student at Loughborough University. To increase the neural network’s efficiency, the team increased the original training data by using data augmentation. The convolutional neural network was augmented 100 times, the team said.
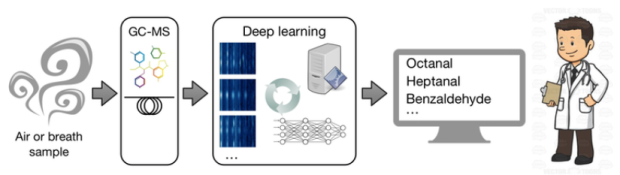
“A team of doctors, nurses, radiographers and medical physicists at the Edinburgh Cancer Centre collected breath samples from participants undergoing cancer treatment. The samples were then analyzed by two teams of chemists and computer scientists. Once a number of compounds were identified manually by the chemists, fast computers were given the data to train deep learning networks. The computation was accelerated by special devices, called GPUs, that can process multiple different pieces of information at the same time. The deep learning networks learned more and more from each breath sample until they could recognize specific patterns that revealed specific compounds in the breath” as posted by Andrea Soltoggio on The Conversation.

3D view of a portion of breath sample data
“Computers equipped with this technology only take minutes to autonomously analyze a breath sample that previously took hours by a human expert,” Soltoggio said. AI is making the whole process cheaper – but above all, it is making it more reliable.
Link to the paper: ResearchGate
(Via: ResearchGate, The Conversation, NVidia)



 satta king gali
satta king gali