DeepMind’s programmers have given the agent a set of virtual sensors (so it can tell whether it’s upright or not, for example) and then incentivize to move forward. The computer works the rest out for itself, using trial and error to come up with different ways of moving. True motor intelligence requires learning how to control and coordinate a flexible body to solve tasks in a range of complex environments. Existing attempts to control physically simulated humanoid bodies come from diverse fields, including computer animation and biomechanics. A trend has been to use hand-crafted objectives, sometimes with motion capture data, to produce specific behaviors. However, this may require considerable engineering effort and can result in restricted behaviors or behaviors that may be difficult to repurpose for new tasks.
True motor intelligence requires learning how to control and coordinate a flexible body to solve tasks in a range of complex environments. Existing attempts to control physically simulated humanoid bodies come from diverse fields, including computer animation and biomechanics. A trend has been to use hand-crafted objectives, sometimes with motion capture data, to produce specific behaviors. However, this may require considerable engineering effort and can result in restricted behaviors or behaviors that may be difficult to repurpose for new tasks.
DeepMind published 3 papers which are as follows:
Emergence of locomotion behaviors in rich environments:-
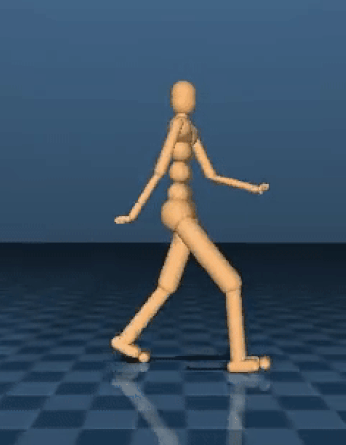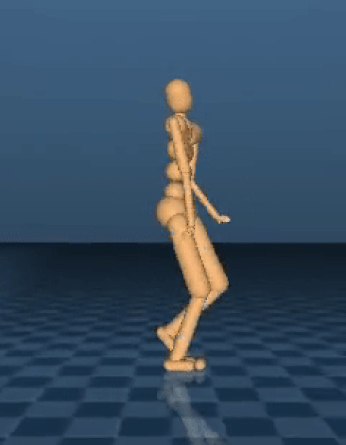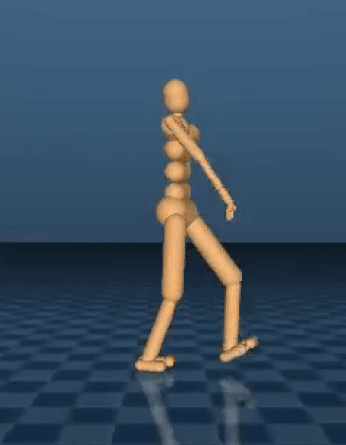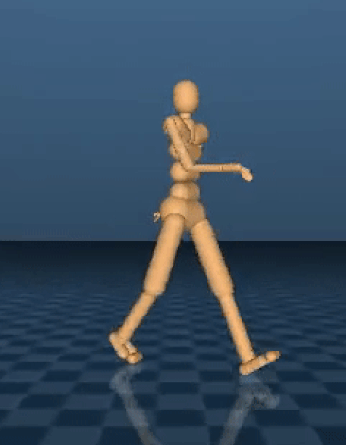
For some AI problems, such as playing Atari or Go, the goal is easy to define – it’s winning. But describing a process such as a jog, a backflip or a jump is difficult because of accurately describing a complex behavior which is a common problem when teaching motor skills to an artificial system. DeepMind explored how sophisticated behaviors can emerge from scratch from the body interacting with the environment using only simple high-level objectives, such as moving forward without falling. DeepMind trained agents with a variety of simulated bodies to make progress across diverse terrains, which require jumping, turning and crouching. The results show that their agents developed these complex skills without receiving specific instructions, an approach that can be applied to train systems for multiple, distinct simulated bodies.

Simulated planar Walker attempts to climb a wall
But how do you describe the process for performing a backflip? Or even just a jump? The difficulty of accurately describing a complex behavior is a common problem when teaching motor skills to an artificial system. In this work, we explore how sophisticated behaviors can emerge from scratch from the body interacting with the environment using only simple high-level objectives, such as moving forward without falling. Specifically, we trained agents with a variety of simulated bodies to make progress across diverse terrains, which require jumping, turning and crouching. The results show our agents develop these complex skills without receiving specific instructions, an approach that can be applied to train our systems for multiple, distinct simulated bodies. The GIFs show how this technique can lead to high-quality movements and perseverance.
Learning human behaviors from motion capture by adversarial imitation:-
The emergent behavior described above can be very robust, but because the movements must emerge from scratch, they often do not look human-like.
DeepMind in their second paper demonstrated how to train a policy network that imitates motion capture data of human behaviors to pre-learn certain skills, such as walking, getting up from the ground, running, and turning.
Having produced behavior that looks human-like, they can tune and repurpose those behaviors to solve other tasks, like climbing stairs and navigating walled corridors.
Robust imitation of diverse behaviors:-
The third paper proposes a neural network architecture, building on state-of-the-art generative models, that is capable of learning the relationships between different behaviors and imitating specific actions that it is shown. After training, their system can encode a single observed action and create a new novel movement based on that demonstration.After training, their system can encode a single observed action and create a new novel movement based on that demonstration.It can also switch between different kinds of behaviors despite never having seen transitions between them, for example switching between walking styles.
(via The Verge, DeepMind Blog)



 satta king gali
satta king gali