A few months ago, Geoffrey Hinton and his team published two papers that introduced a completely new type of a neural network based on Capsules, further to in support of those Capsule Networks, the team published an algorithm called dynamic routing between capsules for the training of such networks.
With Hinton’s capsule network, layers are comprised not of individual Artificial Neural Networks (ANNs), but rather of small groups of ANNs arranged in functional pods, or “capsules.” Each capsule is programmed to detect a particular attribute of the object being classified, thus getting around the need for massive input data sets. This makes capsule networks a departure from the “let them teach themselves” approach of traditional neural nets.
A layer is assigned the task of verifying the presence of some characteristic, and when enough capsules are in agreement on the meaning of their input data, the layer passes on its prediction to the next layer.
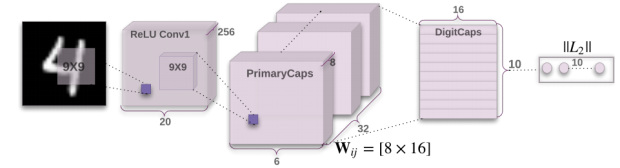
Capsule Net Architecture
A capsule is a nested set of neural layers. So in a regular neural network, you keep on adding more layers. In CapsNet you would add more layers inside a single layer. Or in other words, nesting a neural layer inside another. The state of the neurons inside a capsule capture the above properties of one entity inside an image. A capsule outputs a vector to represent the existence of the entity. The orientation of the vector represents the properties of the entity. The vector is sent to all possible parents in the neural network. For each possible parent, a capsule can find a prediction vector. Prediction vector is calculated based on multiplying its own weight and a weight matrix. Whichever parent has the largest scalar prediction vector product, increases the capsule bond. Rest of the parents decrease their bond. This routing by agreement method is superior to the current mechanism like max-pooling. Max pooling routes based on the strongest feature detected in the lower layer. Apart from dynamic routing, CapsNet talks about adding squashing to a capsule. Squashing is a non-linearity. So instead of adding squashing to each layer like how you do in CNN, you add the squashing to a nested set of layers. So the squashing function gets applied to the vector output of each capsule.
So far, capsule nets have proven equally adept at as traditional neural nets at understanding handwriting, and cut the error rate in half for identifying toy cars and trucks. Impressive, but it’s just a start. The current implantation of capsule networks is, according to Hinton, slower than it will have to be in the end.
(via arxiv, medium blogs, i-programmer, bigthink)
 satta king gali
satta king gali