AI typically needs a plethora of data and a lot of time for something like voice cloning. It needs to listen to hours of recordings. However, a new process could get that down to one minute. Baidu researchers have unveiled an upgraded version of Deep Voice, their text-to-speech synthesis system, that can now, once trained, clone any voice after listening to a few snippets of audio. This capability was enabled by learning shared and discriminative information from speakers. Baidu calls this ‘Voice Cloning’. Voice cloning is expected to have significant applications in the direction of personalization in human-machine interfaces.
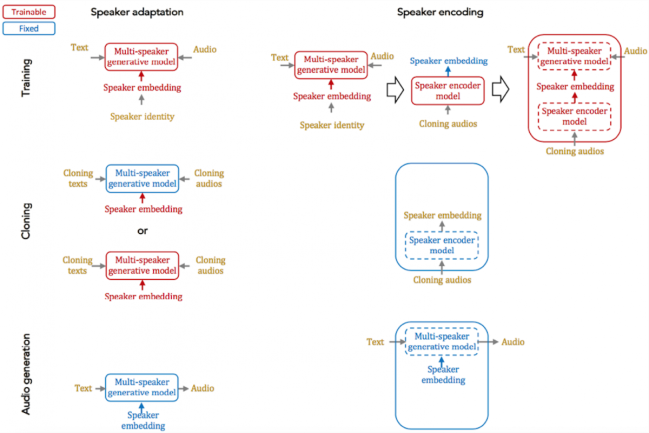
Here, Baidu focuses on two fundamental approaches (refer above figure):
- Speaker Adaption: Speaker adaptation is based on fine-tuning a multi-speaker generative model with a few cloning samples, by using backpropagation-based optimization. Adaptation can be applied to the whole model or only the low-dimensional speaker embeddings. The latter enables a much lower number of parameters to represent each speaker, albeit it yields a longer cloning time and a lower audio quality.
- Speaker Encoding: Speaker encoding is based on training a separate model to directly infer a new speaker embedding from cloning audios that will ultimately be used with a multi-speaker generative model. The speaker encoding model has time-and-frequency-domain processing blocks to retrieve speaker identity information from each audio sample, and attention blocks to combine them in an optimal way.
For detailed information and mathematical explanations, refer the paper by Baidu Research.
However, this technology can also possibly have a downside as this could be tumultuous to people relying upon biometric voice security.
( via MitTechReview, Wiki, BaiduResearch)
 satta king gali
91 club
Hdhub4u
Hdhub4u
satta king gali
91 club
Hdhub4u
Hdhub4u